若泽大数据,带你全面剖析Hive DDL!
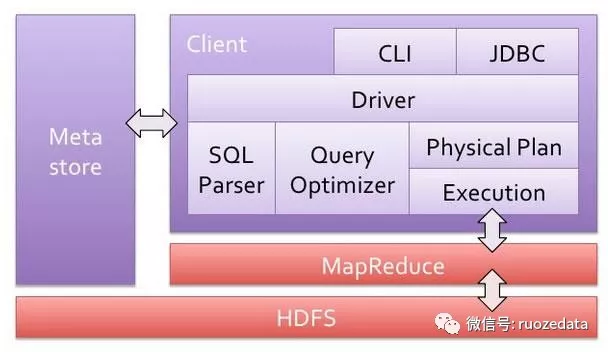
概念
Database
Hive中包含了多个数据库,默认的数据库为default,对应于HDFS目录是/user/hadoop/hive/warehouse,可以通过hive.metastore.warehouse.dir参数进行配置(hive-site.xml中配置)
Table
Hive中的表又分为内部表和外部表 ,Hive 中的每张表对应于HDFS上的一个目录,HDFS目录为:/user/hadoop/hive/warehouse/[databasename.db]/table
Partition
分区,每张表中可以加入一个分区或者多个,方便查询,提高效率;并且HDFS上会有对应的分区目录:
/user/hadoop/hive/warehouse/[databasename.db]/table
DDL(Data Definition Language)
Create Database
1 | CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name |
IF NOT EXISTS:加上这句话代表判断数据库是否存在,不存在就会创建,存在就不会创建。
COMMENT:数据库的描述
LOCATION:创建数据库的地址,不加默认在/user/hive/warehouse/路径下
WITH DBPROPERTIES:数据库的属性
Drop Database
1 | DROP (DATABASE|SCHEMA) [IF EXISTS] database_name |
RESTRICT:默认是restrict,如果该数据库还有表存在则报错;
CASCADE:级联删除数据库(当数据库还有表时,级联删除表后在删除数据库)。
Alter Database
1 | ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); -- (Note: SCHEMA added in Hive 0.14.0) |
Use Database
1 | USE database_name; |
Show Databases
1 | SHOW (DATABASES|SCHEMAS) [LIKE 'identifier_with_wildcards' |
Describe Database
1 | DESCRIBE DATABASE [EXTENDED] db_name; |
Create Table
1 | CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later) |
data_type
1 | : primitive_type |
primitive_type
1 | : TINYINT |
array_type
1 | : ARRAY < data_type > |
map_type
1 | : MAP < primitive_type, data_type > |
struct_type
1 | : STRUCT < col_name : data_type [COMMENT col_comment], ...> |
union_type
1 | : UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later) |
row_format
1 | : DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] |
file_format:
1 | : SEQUENCEFILE |
constraint_specification:
1 | : [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE ] |
注意:
- 如果创建的临时表表名已存在,那么当前session引用到该表名时实际用的是临时表,只有drop或rename临时表名才能使用原始表
- 临时表限制:不支持分区字段和创建索引
EXTERNAL(外部表)
Hive上有两种类型的表,一种是Managed Table(默认的),另一种是External Table(加上EXTERNAL关键字)。它俩的主要区别在于:当我们drop表时,Managed Table会同时删去data(存储在HDFS上)和meta data(存储在MySQL),而External Table只会删meta data。
1 | hive> create external table external_table( |
PARTITIONED BY(分区表)
产生背景:如果一个表中数据很多,我们查询时就很慢,耗费大量时间,如果要查询其中部分数据该怎么办呢,这是我们引入分区的概念。
可以根据PARTITIONED BY创建分区表,一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下;
分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
单分区:
1 | hive> CREATE TABLE order_partition ( |
多分区:
1 | hive> CREATE TABLE order_partition2 ( |
1 | [hadoop@hadoop000 ~]$ hadoop fs -ls /user/hive/warehouse/hive.db |
官网解释:
1 | : DELIMITED |
DELIMITED:分隔符(可以自定义分隔符);
FIELDS TERMINATED BY char:每个字段之间使用的分割;
例:-FIELDS TERMINATED BY ‘\n’ 字段之间的分隔符为\n;
COLLECTION ITEMS TERMINATED BY char:集合中元素与元素(array)之间使用的分隔符(collection单例集合的跟接口);
MAP KEYS TERMINATED BY char:字段是K-V形式指定的分隔符;
LINES TERMINATED BY char:每条数据之间由换行符分割(默认[ \n ])
一般情况下LINES TERMINATED BY char我们就使用默认的换行符\n,只需要指定FIELDS TERMINATED BY char。
创建demo1表,字段与字段之间使用\t分开,换行符使用默认\n:
1 | hive> create table demo1( |
创建demo2表,并指定其他字段:
1 | hive> create table demo2 ( |
创建表(拷贝表结构及数据,并且会运行MapReduce作业)
1 | CREATE TABLE emp ( |
加载数据
1 | LOAD DATA LOCAL INPATH "/home/hadoop/data/emp.txt" OVERWRITE INTO TABLE emp; |
复制整张表
1 | hive> create table emp2 as select * from emp; |
复制表中的一些字段
1 | create table emp3 as select empno,ename from emp; |
LIKE
使用like创建表时,只会复制表的结构,不会复制表的数据
1 | hive> create table emp4 like emp; |
并没有查询到数据
desc formatted table_name
查询表的详细信息
1 | hive> desc formatted emp; |
col_name data_type comment
1 | empno int |
Detailed Table Information
1 | Database: hive |
Storage Information
1 | SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
通过查询可以列出创建表时的所有信息,并且我们可以在mysql中查询出这些信息(元数据)select * from table_params;
查询数据库下的所有表
1 | hive> show tables; |
查询创建表的语法
1 | hive> show create table emp; |
指定PURGE后,数据不会放到回收箱,会直接删除
DROP TABLE删除此表的元数据和数据。如果配置了垃圾箱(并且未指定PURGE),则实际将数据移至.Trash / Current目录。元数据完全丢失
删除EXTERNAL表时,表中的数据不会从文件系统中删除
Alter Table
重命名
1 | hive> alter table demo2 rename to new_demo2; |
查询结果
1 | hive> select * from dept; |
查看分区语句
1 | hive> show partitions dept; |
按分区查询
1 | hive> select * from dept where dt='2018-08-08'; |
